地址:http://www.heibanke.com/lesson/crawler_ex02/
本关的难点就是所谓的两层认证,需要获取处理cookie。
刚进入页面时没看懂是怎么玩,以为到这就结束了,抱着试试看的态度注册了下。

注册登录后,发现是一个记账点之类的,网页还没有跳转到题目网页,还不知道怎么玩。
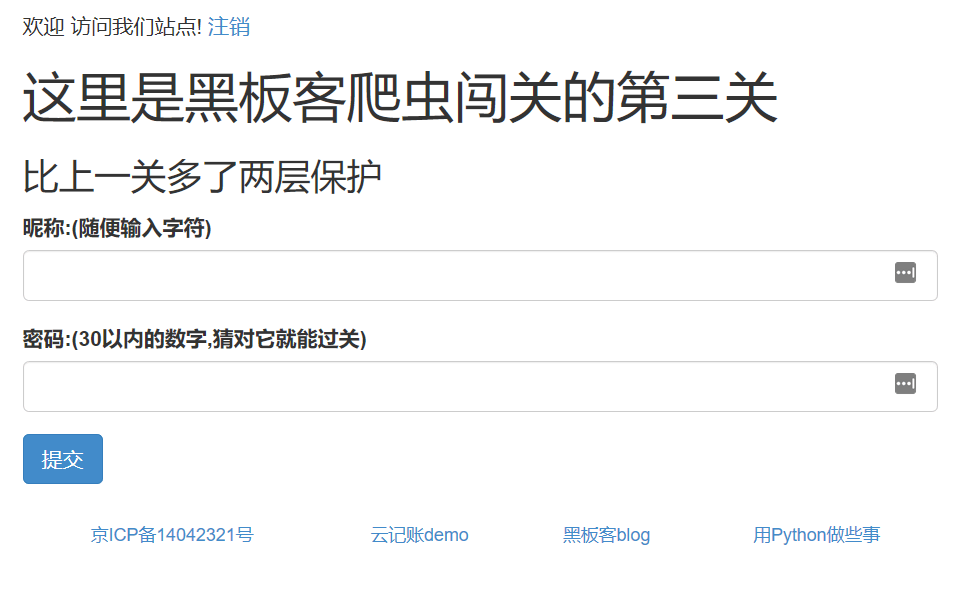
重新从题目地址进入后,发现可以玩了:
使用selenium实现
使用selenium实现方式好像不涉及验证之类的问题,因为完全是模拟的人类登录浏览器的过程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44# coding=utf-8
from selenium import webdriver
url = 'http://www.heibanke.com/lesson/crawler_ex02/'
browser = webdriver.Chrome()
# browser = webdriver.Firefox()
browser.get(url)
# 登录
username = browser.find_element_by_id('id_username')
username.clear()
username.send_keys('liuhaha')
password = browser.find_element_by_id('id_password')
password.clear()
password.send_keys('123456')
password.submit()
# 重新进入问题页面
browser.get(url)
for i in range(31):
username = browser.find_element_by_name('username')
username.clear()
username.send_keys('liuhaha')
password = browser.find_element_by_id('id_password')
password.clear()
password.send_keys(i)
# FireFox下异步,Chrome下同步,submit方法会等待页面加载完成后返回
# password.submit()
# 两种浏览器下click()方法都会等到加载完成后返回
browser.find_element_by_id('id_submit').click()
returnText = browser.find_element_by_tag_name('h3')
print(returnText.text + ', password ' + str(i))
if u"成功" in returnText.text:
break
browser.back()
browser.quit()
requests实现
实现思路
题目中提到了两层保护,是哪两层呢?
首先,多了账号登陆一层,还有一层是什么呢?重新登陆,打开firebug记录一下整个流程。
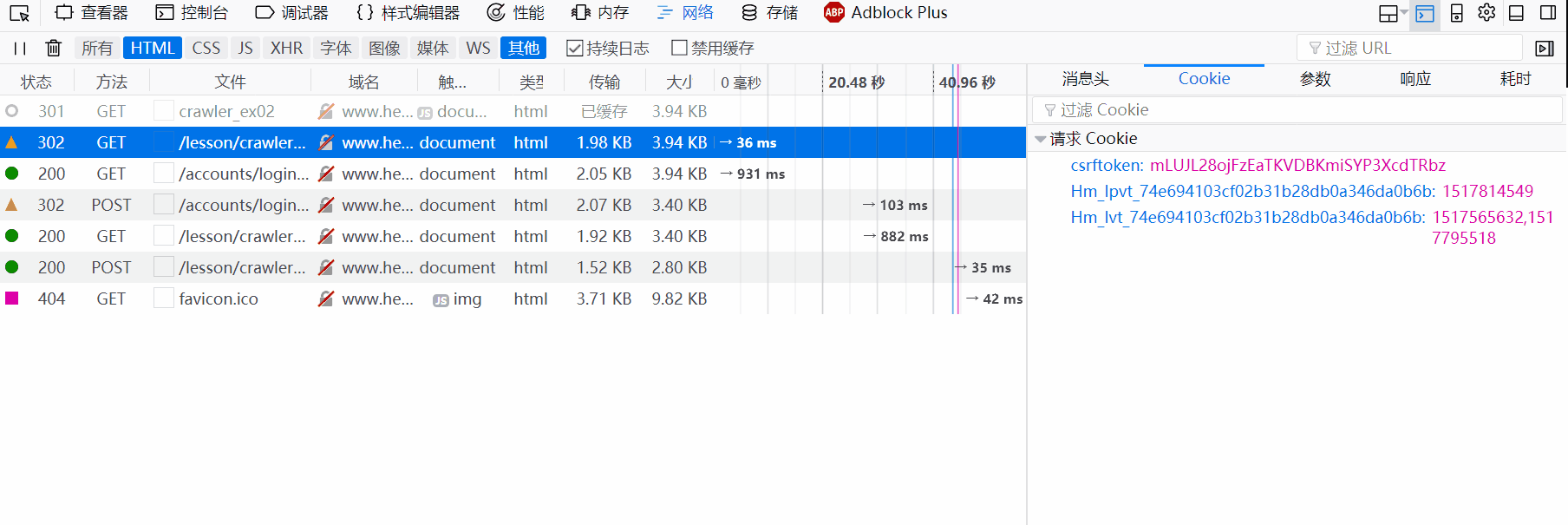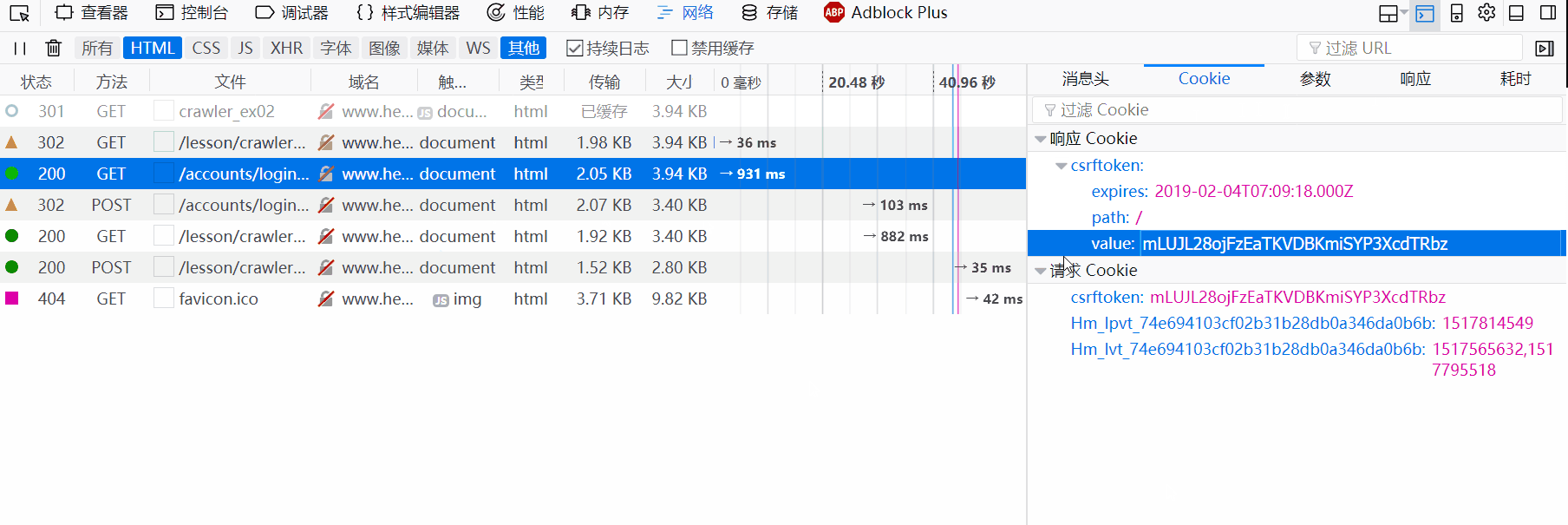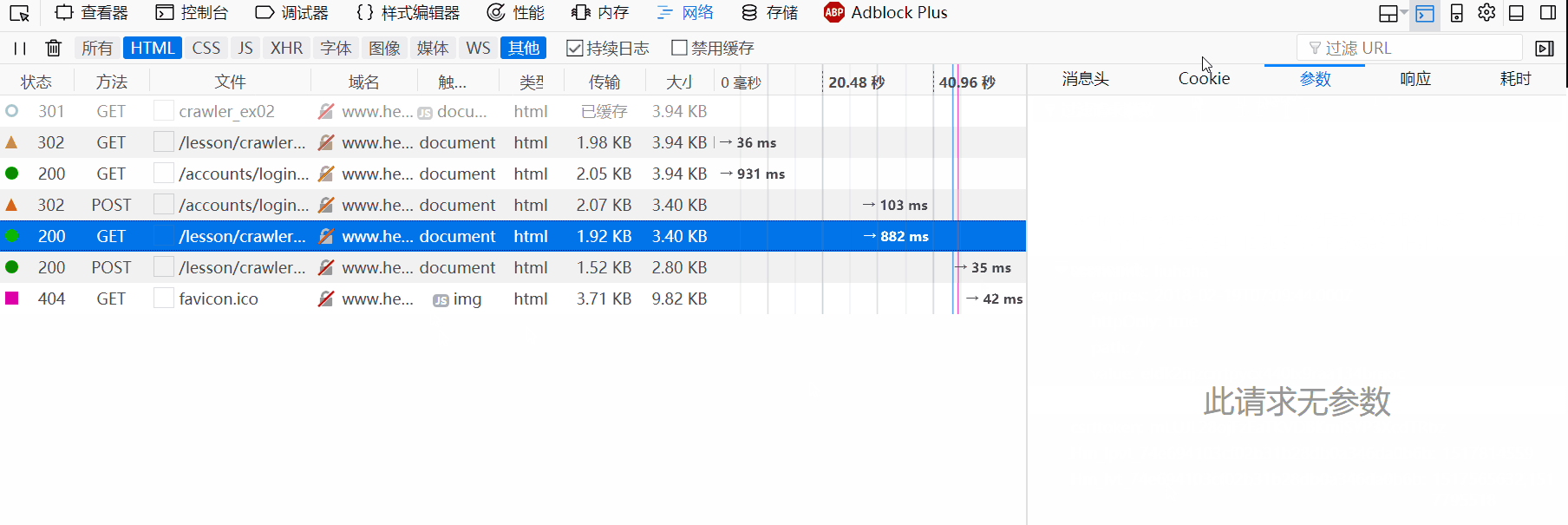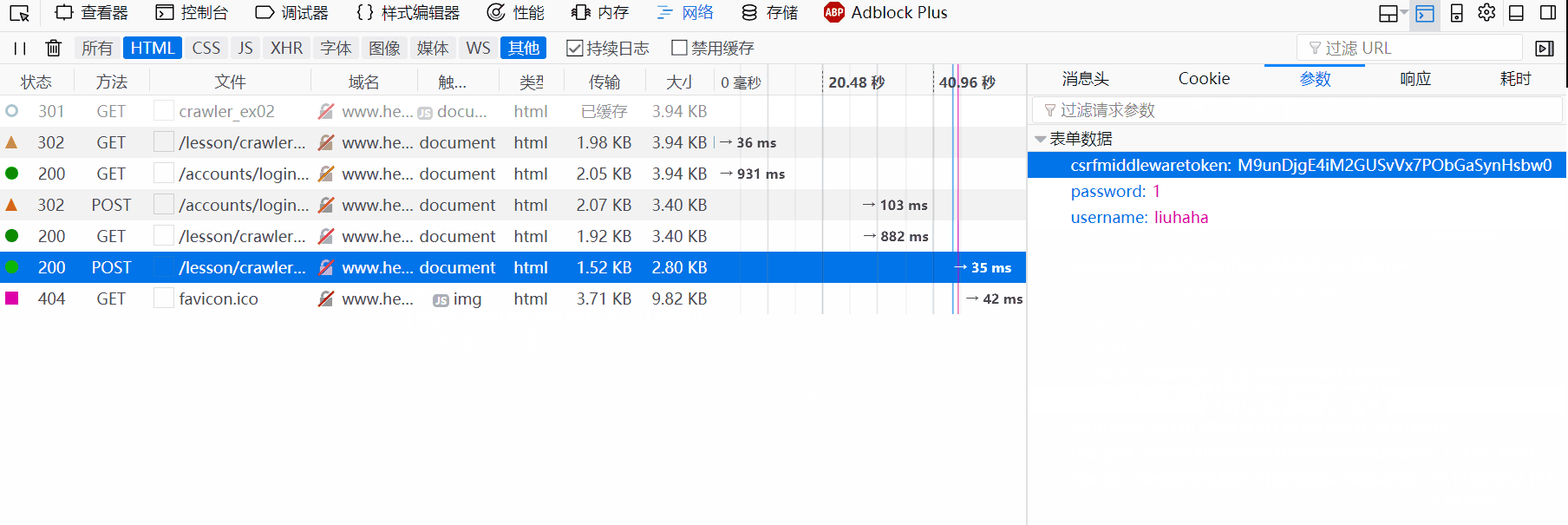
值得注意的一点是cookies值会存在两个地方:一个是请求标头,一个是请求正文,两者可能相同可能不同,存在请求正文的是POST请求,因此要在post data中附带上cookie值。
整个访问的详细流程:
- 浏览器向URL发出GET请求,得到一个302的重定向的响应,响应标头中包含了一个Location字段,告诉浏览器新的访问地址LOGIN_URL。如果之前用同样的浏览器闯过第一关或第二关,此请求的请求标头仍然会带上cookie,但并无实际作用,可忽略。
- 浏览器从第一步响应结果得到新的地址,并向此地址发出GET请求。响应标头中会set一个cookie,如果之前访问过该网站,那么此cookie会和请求标头的cookie一样。不管怎样,此cookie都将作为以后访问过程中的依据之一。我们将此返回的cookie记录为c1。
- 浏览器向再向LOGIN_URL发出POST请求,得到一个包含URL的302重定向的响应。除了请求正文中的username和password字段外,请求标头和请求正文中都附带上第二步中的cookie c1,返回的响应标头中附带上了两个新的cookie,其中一个会在下次访问的请求标头中覆盖原来的cookie c1。我们将此返回的cookies记录为c2。
- 向URL提交POST请求,请求标头附带的是第3步的cookie c2,请求正文是昵称密码和cookie c2的其中一个值。
其中:
- URL=
http://www.heibanke.com/lesson/crawler_ex02/ - LOGIN_URL=
http://www.heibanke.com/accounts/login/?next=/lesson/crawler_ex02/
实现代码
1 | # coding=utf-8 |


