本文主要包括 Python 遍历方法、公共方法、异常处理、模块、列表推导式等内容。
遍历
通过 for ... in ...: 的语法结构,我们可以遍历字符串、列表、元组、字典等数据结构。
字符串、列表、元组遍历
1 | for i in 'abc': |
字典遍历
1 | for key in dict.keys(): |
enumerate()
enumerate(sequence, [start=0]) - 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
1 | l = ['a', 'b', 'c'] |
公共方法
运算符
| 运算符 | Python 表达式 | 结果 | 描述 | 支持的数据类型 |
|---|---|---|---|---|
| + | [1, 2] + [3, 4] | [1, 2, 3, 4] | 合并 | 字符串、列表、元组 |
| * | ‘Hi!’ * 4 | [‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’] | 复制 | 字符串、列表、元组 |
| in | 3 in (1, 2, 3) | True | 元素是否存在 | 字符串、列表、元组、字典 |
| not in | 4 not in (1, 2, 3) | True | 元素是否不存在 | 字符串、列表、元组、字典 |
Python函数相关
python内置函数
| 方法 | 描述 |
|---|---|
| len(item) | 计算容器中元素个数 |
| max(item) | 返回容器中元素最大值 |
| min(item) | 返回容器中元素最小值 |
| del(item) | 删除变量 |
函数参数
缺省参数
调用函数时,缺省参数的值如果没有传入,则被认为是默认值。
1 | # 缺省参数 |
输出结果为:1
2name is liuha, age is 20
name is liu2, age is 5
注意:带有默认值的参数一定要位于参数列表的最后面。否则会报错:
SyntaxError: non-default argument follows default argument
不定长参数
有时可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,声明时不会命名。
基本语法如下:1
2
3def functionname([formal_args,] *args, **kwargs):
function_suite
return [expression]
加了 * 的变量 args 会存放所有未命名的变量参数,args 为元组;而加 ** 的变量 kwargs 会存放命名参数,即形如 key=value 的参数, kwargs 为字典。
1 | # 可变长参数 |
输出:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
221
2
----------
name is liuha, age is 20
name is liu2, age is 5
----------
a = 1
b = 2
args = (3, 4)
kwargs = {'k1': 2, 'k2': 3}
-----
a = 1
b = 2
args = (3,)
kwargs = {'k1': 2, 'k2': 3}
-----
a = 1
b = 2
args = ()
kwargs = {'k1': 3}
引用传参
可变类型与不可变类型的变量分别作为函数参数时,会有什么不同吗?
Python中函数参数是引用传递(注意不是值传递)。对于不可变类型(string,integer,tuple),因变量不能修改,所以运算不会影响到变量自身;而对于可变类型(list,dict),函数体中的运算有可能会更改传入的参数变量。
1 | # 引用传参 |
输出为:1
2
3
4
5
6
7
8a = 1
b = 2
args = ()
kwargs = {'k1': 3}
a = 1
b = 1
a_list = [2, 3, 2, 3]
b_list = [2, 3]
注意
a *= 2和a = a*2的不同,对于可变类型,a = a*2会重新分配一个变量 a,而之前的 a 是不会变的。
匿名函数
用 lambda 关键词能创建小型匿名函数。这种函数得名于省略了用 def 声明函数的标准步骤。
lambda 函数的语法只包含一个语句,如下:
1 | lambda [arg1 [,arg2,.....argn]]:expression |
- lambda 函数能接收任何数量的参数但只能返回一个表达式的值。
- 匿名函数不能直接调用 print,因为 lambda 需要一个表达式
1 | sum = lambda a,b : a+b |
应用场合
1 | > stus |
Python 异常处理
1 | import time |
- 当捕获多个异常时,可以把要捕获的异常的名字,放到 except 后,并使用元组的方式仅进行存储
- 在
try...except...中也是如此,即如果没有捕获到异常,那么就执行else中的事情 - 在程序中,如果一个段代码必须要执行,即无论异常是否产生都要执行,那么此时就需要使用 finally。
异常传递
- 如果 try 嵌套,那么如果里面的 try 没有捕获到这个异常,那么外面的 try 会接收到这个异常,然后进行处理,如果外边的 try 依然没有捕获到,那么再进行传递。
- 如果一个异常是在一个函数中产生的,例如
函数 A ---->函数 B ---->函数 C,而异常是在函数 C 中产生的,那么如果函数 C 中没有对这个异常进行处理,那么这个异常会传递到函数 B 中,如果函数 B 有异常处理那么就会按照函数 B 的处理方式进行执行;如果函数 B 也没有异常处理,那么这个异常会继续传递,以此类推。如果所有的函数都没有处理,那么此时就会进行异常的默认处理,即通常见到的那样。
1 | # coding=utf-8 |
运行结果:
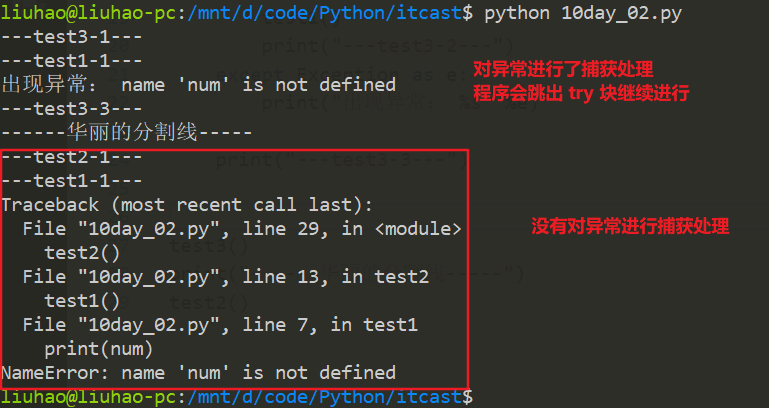
- 注意观察执行结果图中,当调用 test3 函数时,在 test1 函数内部产生了异常,此异常被传递到 test3 函数中完成了异常处理,而当异常处理完后,并没有返回到函数 test1 中进行执行,而是在函数 test3 中继续执行
模块
模块导入
模块就好比是工具包,要想使用这个工具包中的工具(就好比函数),就需要导入这个模块。
import
在 Python 中用关键字 import 来引入某个模块,形如:
1 | import module1,mudule2... |
通过这种方式引入的时候,调用函数时只能给出函数名,不能给出模块名,但是当两个模块中含有相同名称函数的时候,后面一次引入会覆盖前一次引入。也就是说假如模块 A 中有函数 function(),在模块 B 中也有函数 function(),如果引入 A 中的 function 在先、B 中的 function 在后,那么当调用 function 函数的时候,是去执行模块 B 中的 function 函数。
如果想一次性引入 math 中所有的东西,还可以通过
from math import *来实现
from…import
有时候我们只需要用到模块中的某个函数,只需要引入该函数即可,此时可以用下面方法实现:
1 | from modname import name1[, name2[, ... nameN]] |
as
通过 as 可以赋予引入的包一个别名:
1 | import math as m |
模块引用顺序
当你导入一个模块,Python 解析器对模块位置的搜索顺序是:
- 当前目录
- 如果不在当前目录,Python 则搜索在 shell 变量 PYTHONPATH 下的每个目录。
- 如果都找不到,Python 会察看默认路径。UNIX 下,默认路径一般为
/usr/local/lib/python/ - 模块搜索路径存储在 system 模块的 sys.path 变量中。变量里包含当前目录,PYTHONPATH 和由安装过程决定的默认目录。
模块制作
自定义模块模块
在 Python 中,每个 Python 文件都可以作为一个模块,模块的名字就是文件的名字。
比如有这样一个文件 test.py,在 test.py 中定义了函数 add:
1 | # coding=utf-8 |
调用自定义模块
那么在其他文件中就可以先 import test,然后通过 test.add(a,b) 来调用了,当然也可以通过 from test import add 来引入。
1 | import test |
测试模块
在实际开中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在 py 文件中添加一些测试信息,例如:
1 | # coding=utf-8 |
test.py 中的测试代码,应该是单独执行 test.py 文件时才应该执行的,不应该是其他的文件中引用而执行。
可以根据 __name__ 变量的结果能够判断出,是直接执行的 python 脚本还是被引入执行的,从而能够有选择性的执行测试代码。
1 | # coding=utf-8 |
__all__ 变量
python 模块中的 __all__ 属性,可用于模块导入时限制,如:from module import *。
此时被导入模块若定义了 __all__ 属性,则只有 __all__ 内指定的属性、方法、类可被导入。若没定义,则导入模块内的所有公有属性,方法和类。
因此,使用 __all__ 可以隐藏不想被 import 的默认值。
1 | # coding=utf-8 |
测试结果:
1 | from test import * |
模块发布
- mymodule 目录如下:
1 | . |
- 编辑 setup.py 文件:
py_modules 需指明所需包含的 py 文件。
1 | from distutils.core import setup |
- 构建模块
1 | python setup.py build1 |
构建后的目录结构:
1 | . |
- 生成发布包
1 | python setup.py sdist |
打包后,生成最终发布压缩包 liuhao-1.0.tar.gz,目录结构:
1 | . |
模块安装和使用
- 找到模块的压缩包
- 解压
- 进入文件夹
- 执行命令
python setup.py install
如果在 install 的时候,执行目录安装,可以使用
python setup.py install --prefix=安装路径
在程序中,使用 from import 即可完成对安装的模块使用
1 | from 模块名 import 模块名或者* |
列表推导式
- 基本方式
1 | [x for x in range(3)] |
- 结合 if
1 | [x for x in range(3,10) if x%2 == 0] |
- 多个 for 循环
1 | [(x,y) for x in range(3) for y in range(4) if x%2 ==0 if y%3 == 0] |


