本文使用的高可用架构是 Keepalived + HAproxy,用 HAproxy 来做 RabbitMQ 负载均衡和高可用,用 Keepalived 来保证 HAproxy 的高可用。
RabbitMQ 集群的安装过程这里不再赘述,可以参考 https://blog.csdn.net/WoogeYu/article/details/51119101。
这里使用的三节点集群的安装方式,规划如下:
| 组件 | IP | 端口 |
|---|---|---|
| RabbitMQ 主 | 192.168.151.7 | 5672 |
| RabbitMQ 从 | 192.168.151.18 | 5672 |
| RabbitMQ 从 | 192.168.151.19 | 5672 |
| HAproxy 主 | 192.168.151.18 | |
| HAproxy 从 | 192.168.151.19 | |
| Keepalived 主 | 192.168.151.18 | |
| Keepalived 从 | 192.168.151.19 | |
| VIP | 192.168.151.108 |
RabbitMQ 集群安装
在 192.168.151.7、192.168.151.18、192.168.151.19 三个节点上分别安装配置。
安装
1 | yum -y install rabbitmq-server |
配置
1 | rabbitmqctl add_user admin admin |
- 局域网配置
分别在三个节点的 /etc/hosts 下设置相同的配置信息
1 | 192.168.151.7 HRB-PCRP1-M-BCCLM-CTL7 |
- 设置不同节点间同一认证的 Erlang Cookie
采用从主节点 copy 的方式保持 Cookie 的一致性。
1 | # scp /var/lib/rabbitmq/.erlang.cookie 192.168.151.18:/var/lib/rabbitmq |
- 使用 -detached 运行各节点
1 | rabbitmqctl stop |
- 查看各节点的状态
1 | rabbitmqctl cluster_status |
- 创建并部署集群,以 192.168.151.7 节点为例:
1 | # rabbitmqctl stop_app |
- 查看集群状态
1 | # rabbitmqctl cluster_status |
RabbitMQ 集群至此安装完成。可以通过访问各节点的 http://192.168.151.7:15672/ 管理页面查看 RabbitMQ 状态。用户名密码使用之前配置的 admin/admin。
Keepalived 监控 192.168.151.18、192.168.151.19 上的 HAproxy,利用 Keepalived 的 VIP 漂移技术,若两台服务器上的 HAprox 都工作正常,则 VIP 与优先级别高的服务器(主服务器)绑定,当主服务器当掉时,则与从服务器绑定,而 VIP 则是暴露给外部访问的 IP;HAproxy 利用 Keepalived 生产的 VIP 对多台 RabbitMQ 进行读负载均衡。
下面对上面的 RabbitMQ 集群进行高可用配置,HAproxy 和 Keepalived 的安装方法这里不再赘述。
高可用架构
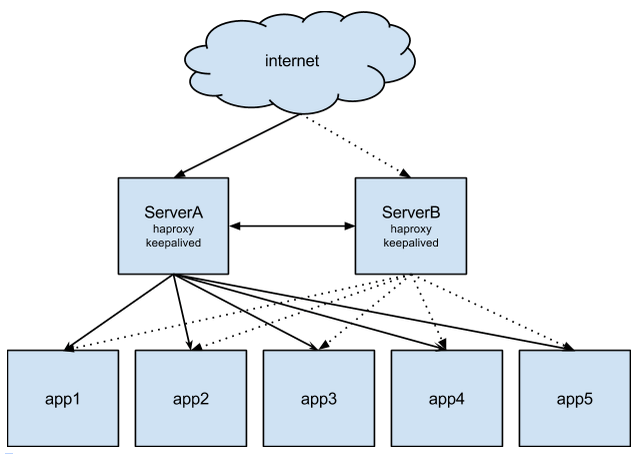
其中 Keepalived 来控制 HAproxy 的高可用,HAproxy 的作用是控制下层应用的负载均衡,同时可以用来保证下层应用的高可用。
HAproxy
HAproxy 是一个七层的负载均衡高度器,和 nginx 是属于一个层次上的,而 lvs 是一个四层的负载均衡高度器,它最多只能工作在 TCP/IP 协议栈上,所以对于代理转发,HAproxy 做的可以比 lvs 更细腻。
HAProxy 提供高可用性、负载均衡以及基于 TCP 和 HTTP 应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。HAProxy 特别适用于那些负载特大的 web 站点,这些站点通常又需要会话保持或七层处理。HAProxy 运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中,同时可以保护你的 web 服务器不被暴露到网络上。
HAproxy 配置
这里仅列出了主要内容。
1 | ####################HAProxy配置中分成五部分内容,当然这些组件不是必选的,可以根据需要选择部分作为配置。 |
这里使用了一个 listen 块来同时实现前端和后端,也可以由前端(frontend)和后端(backend)配置。
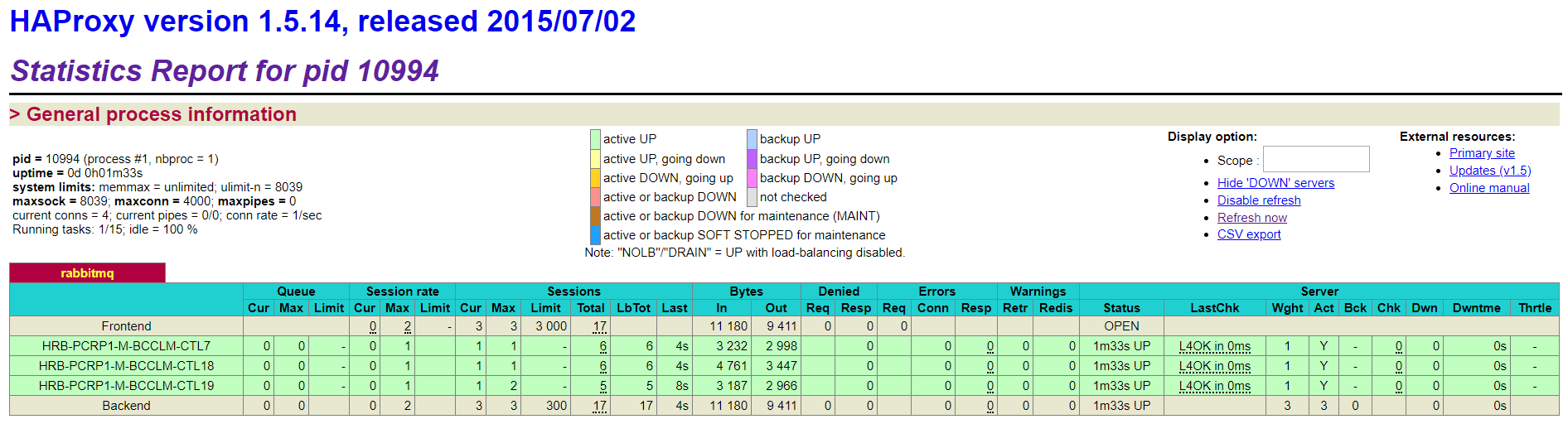
最后我们打开 http://192.168.151.18:8100/stats,看一下监控页面,如果显示出正常就表明已经将 HAProxy 负载均衡配置好了!
注意点
启动 HAproxy 时可能会出现 cannot bind socket 的异常,这是因为 HAproxy 配置中使用了 VIP,但此时还没有启动 Keepalived,那么就还没有 VIP 绑定。
这时需要在 /etc/sysctl.conf 文件中配置如下内容:
1 | net.ipv4.ip_nonlocal_bind = 1 # 意思是启动haproxy的时候,允许忽视VIP的存在 |
然后运行 sysctl –p 使其生效。
Keepalived
Keepalived 的作用是检测服务器的健康状态,在所有可能出现单点故障的地方为其提供高可用。如果有一台服务器死机,或工作出现故障,Keepalived 将检测到,并将有故障的服务器从系统中剔除,当服务器工作正常后 Keepalived 自动将服务器加入到服务器群中,这些工作全部自动完成,不需要人工干涉,需要人工做的只是修复故障的服务器。
这里使用的实现方式是单活方式,即主节点的 HAproxy 正常运行,备节点的会被停止。当主节点的出现故障时,备节点的 HAproxy 会自动启动。当主节点的恢复后,备节点的会自动停止。
当然 Keepalived 的高可用控制不止这一种,也可以有其他配置方式。
Keepalived 主节点配置
1 | vrrp_script chk_haproxy { |
Keepalived 备节点
1 | vrrp_instance haproxy { |
notify.sh 脚本
放在 /etc/keepalived/ 目录下,并赋予可执行权限。
1 | #!/bin/bash |
Keepalived 执行过程
MASTER - 初始 priority 为 100,BACKUP - 初始 priority 为 99
模拟 MASTER 产生故障:
- 当检测到 chk_haproxy 执行结果为 down 时,priority 每次减少 2,变为 98;低于 BACKUP 的 priority;
- 此时 MASTER 变成 BACKUP;
- 同时 BACKUP 变成 MASTER,同时执行 notify_master 的脚本文件(启动haproxy);
模拟 MASTER 故障恢复:
- 当 MASTER 节点的 HAproxy 恢复后,原 MASTER 的优先级又变为 100,高于原 BACKUP 的 priority;
- 此时原 MASTER 由 BACKUP 又抢占成了 MASTER;
- 同时原 BACKUP 由 MASTER 又变了 BACKUP,同时执行 notify_backup 的脚本文件(关闭haproxy);
参考:


