上回我们主要研究了为什么使用索引,以及索引的数据结构。今天带你了解如何设计高性能的索引。
其中,有这么一个点,说的是 InnoDB 引擎中使用的是聚簇索引,其主索引的实现树中的叶子结点存储的是完整的数据记录,而辅助索引中存储的则只是辅助键和主键的值。
这样在用辅助索引进行查询时,会先查出主键的值,然后再去主索引中根据主键的值查询目标值。
比如,假想一个表如下图存储了 4 行数据。其中 Id 作为主索引,Name 作为辅助索引。
| Id | Name | Company |
|---|---|---|
| 5 | Gates | Microsoft |
| 7 | Bezos | Amazon |
| 11 | Jobs | Apple |
| 14 | Ellison | Oracle |
对于聚簇索引,若使用主键索引进行查询,select * from tab where id = 14 这样的条件查找主键,则按照 B+ 树的检索算法即可查找到对应的叶节点,之后获得行数据。
若使用辅助索引进行查询,对 Name 列进行条件搜索,则需要两个步骤:
1、第一步在辅助索引 B+ 树中检索 Name,到达其叶子节点获取对应的主键值。
2、第二步根据主键值在主索引 B+ 树中再执行一次 B+ 树检索操作,最终到达叶子节点即可获取整行数据。
上面这个过程称为回表。
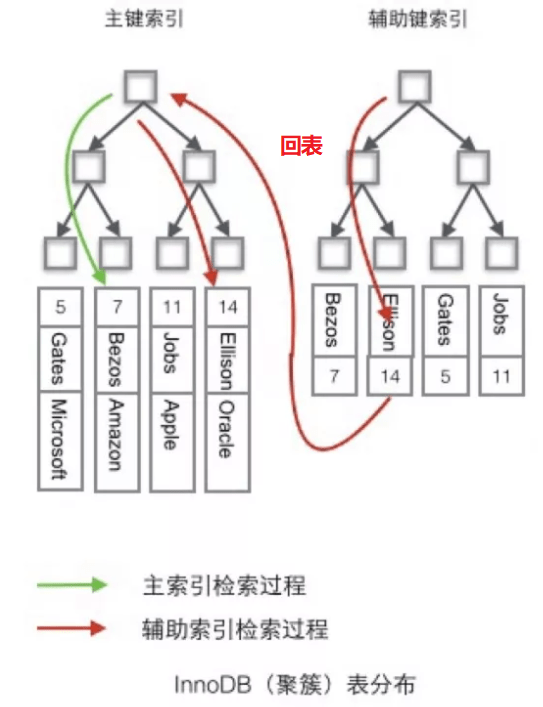
回表:在数据中,当查询数据的时候,在索引中查找索引后,获得该行的 rowid,根据 rowid 再查询表中数据,就是回表。
显然,使用辅助索引出现了回表操作,这势必会影响查询性能,那有什么办法能够减少回表吗?
下面就开始我们的主题:如何让 MySQL 索引更高效!
覆盖索引
上面,我们查询的是 select *,如果是根据 Name 查询 Id 呢?即 select Id from tab where Name='Jobs'。
很明显,由于辅助索引 Name 上已经存储了 Id 的值,所以这时,查询便不会再次回表查询。
如果索引已经包含了所有满足查询需要的数据,这时我们称之为覆盖索引(Covering Index),这时就不再需要回表操作。
覆盖索引是一种非常强大的工具,能大大提高查询性能,只需要读取索引而不用读取数据有以下一些优点:
1、索引条目通常远小于数据行大小,只需要读取索引,则 MySQL 会极大地减少数据访问量。
2、因为索引是按照列值顺序存储的,所以对于 IO 密集的范围查找会比随机从磁盘读取每一行数据的 IO 少很多。
3、覆盖索引对 InnoDB 表特别有用。因为 InnoDB 的辅助索引在叶子节点中保存了行的主键值,所以如果二级主键能够覆盖查询,则可以避免对主键索引的二次查询;
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
联合索引/最左匹配原则
又名复合索引,由两个或多个列的索引。
它规定了 MySQL 从左到右地使用索引字段,对字段的顺序有一定要求。
另外,一个查询可以只使用索引中的一部分,更准确地说是最左侧部分(最左优先),这就是传说中的最左匹配原则。
即最左优先,如:
如果有一个 2 列的索引 (col1,col2),则相当于已经对 (col1)、(col1,col2) 上建立了索引;
如果有一个 3 列索引 (col1,col2,col3),则相当于已经对 (col1)、(col1,col2)、(col1,col2,col3) 上建立了索引;
但是 (col2,col3) 上并没有。
假定数据表有一个包含 2 列的联合索引(a, b),则索引的 B+ 树结构可能如下:
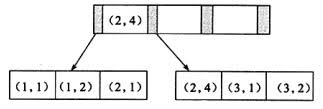
键值都是排序的,通过叶子节点可以逻辑上顺序的读出所有数据。
数据(1,1)(1,2)(2,1)(2,4)(3,1)(3,2)是按照(a,b)先比较 a 再比较 b 的顺序排列。
所以从全局看,a 是全局有序的,而 b 则不是。
基于上面的结构,对于以下查询显然是可以使用(a,b)这个联合索引的:
1 | select * from table where a=xxx and b=xxx ; |
但是对于下面的 sql 是不能使用这个联合索引的,因为叶子节点的 b 值,1,2,1,4,1,2 显然不是排序的。
1 | select * from table where b=xxx |
只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
注意
1、主键字段其实跟所有非主键索引建立了联合索引,只是说如果主键字段没有在联合索引中明确声明,只会在其他索引中处于最右边;
2、最左前缀匹配原则,MySQL 会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。
比如 a = 1 and b = 2 and c > 3 and d = 4 如果建立 (a,b,c,d) 顺序的索引,d 是用不到索引的,如果建立 (a,b,d,c) 的索引,则都可以用到,a,b,d 的顺序可以任意调整。
3、= 和 in 的条件可以乱序
MySQL 的查询优化器会帮你优化成索引可以识别的形式。MySQL 查询优化器会判断纠正 SQL 语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。
为什么要使用联合索引?
1、 减少开销
“一个顶三个”。建一个联合索 引(col1,col2,col3),实际相当于建了 (col1),(col1,col2),(col1,col2,col3) 三个索引。
每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
2、 覆盖索引
对联合索引 (col1,col2,col3),如果有如下的sql: select col1,col2,col3 from test where col1=1 and col2=2。那么 MySQL 可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机 IO 操作。
减少 io 操作,特别的随机 io 其实是 dba 主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
3、 效率高
索引列越多,通过索引筛选出的数据越少。
有 1000W 条数据的表,有如下sql: select col1,col2,col3 from table where col1=1 and col2=2 and col3=3,假设假设每个条件可以筛选出 10% 的数据。
如果只有单值索引,那么通过该索引能筛选出 1000W_10%=100w 条数据,然后再回表从 100w 条数据中找到符合 col2=2 and col3= 3 的数据,然后再排序,再分页;
如果是联合索引,通过索引筛选出 1000w_10% 10% 10%=1w,效率提升可想而知!
索引下推
索引条件下推(ICP:index condition pushdown)是 MySQL 中一个常用的优化,尤其是当 MySQL 需要从一张表里检索数据时。
ICP(index condition pushdown)是 MySQL 利用索引(二级索引)元组和筛字段在索引中的 WHERE 条件从表中提取数据记录的一种优化操作。
ICP 的思想是:存储引擎在访问索引的时候检查筛选字段在索引中的 where 条件,如果索引元组中的数据不满足推送的索引条件,那么就过滤掉该条数据记录。
ICP(优化器)尽可能的把 index condition 的处理从 server 层下推到存储引擎层。
存储引擎使用索引过滤不相关的数据,仅返回符合 index condition 条件的数据给 server 层。也是说数据过滤尽可能存储引擎层进行,而不是返回所有数据给 server 层,然后后再根据 where 条件进行过滤。
下推过程
优化器没有使用 ICP 时
数据访问和提取的过程如下:
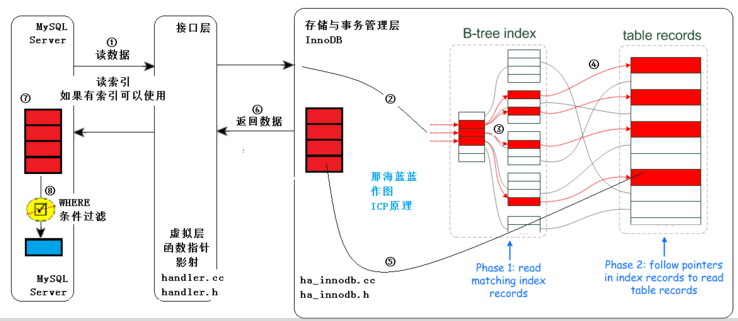
①:MySQL Server 发出读取数据的命令,调用存储引擎的索引读或全表表读。此处进行的是索引读。
②、③:进入存储引擎,读取索引树,在索引树上查找,把满足条件的(红色的)从表记录中读出(步骤 ④,通常有 IO)。
⑤:从存储引擎返回标识的结果。
以上,不仅要在索引行进行索引读取(通常是内存中,速度快。步骤 ③),还要进行进行步骤 ④,通常有 IO。
⑥:从存储引擎返回查找到的多条数据给 MySQL Server,MySQL Server 在 ⑦ 得到较多的元组。
⑦–⑧:依据 WHERE 子句条件进行过滤,得到满足条件的数据。
注意在 MySQL Server 层得到较多数据,然后才过滤,最终得到的是少量的、符合条件的数据。
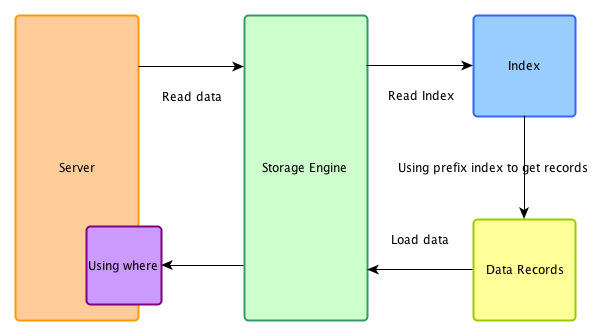
在不支持 ICP 的系统下,索引仅仅作为 data access 使用。
优化器使用ICP时
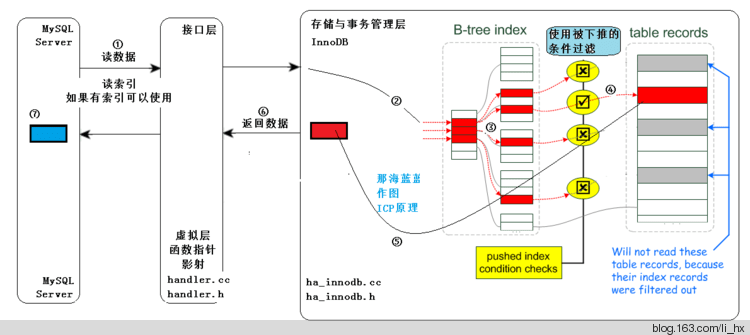
①:MySQL Server 发出读取数据的命令,过程同图一。
②、③:进入存储引擎,读取索引树,在索引树上查找,把满足已经下推的条件的(红色的)从表记录中读出(步骤 ④,通常有 IO);
⑤:从存储引擎返回标识的结果。
此处,不仅要在索引行进行索引读取(通常是内存中,速度快。步骤 ③),还要在 ③ 这个阶段依据下推的条件进行进行判断,不满足条件的,不去读取表中的数据,直接在索引树上进行下一个索引项的判断,直到有满足条件的,才进行步骤 ④ ,这样,较没有 ICP 的方式,IO 量减少。
⑥:从存储引擎返回查找到的少量数据给 MySQL Server,MySQL Server 在 ⑦ 得到少量的数据。
因此比较图一无 ICP 的方式,返回给 MySQL Server 层的即是少量的、 符合条件的数据。
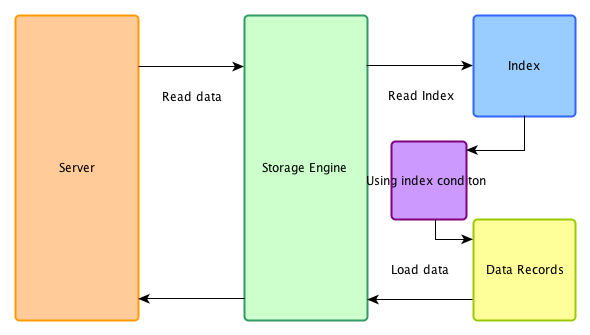
在 ICP 优化开启时,在存储引擎端首先用索引过滤可以过滤的 where 条件,然后再用索引做 data access,被 index condition 过滤掉的数据不必读取,也不会返回 server 端。
举例
比如:
1 | SELECT * FROM employees |
在没有 ICP 时,首先通过索引前缀从存储引擎中读出所有 first_name 为 Mary 的记录,然后在 server 端用 where 筛选 last_name 的 like 条件;
而启用 ICP 后,由于 last_name 的 like 筛选可以通过索引字段进行,那么存储引擎内部通过索引与 where 条件的对比来筛选掉不符合 where 条件的记录,这个过程不需要读出整条记录,同时只返回给 server 筛选后条记录,因此提高了查询性能。
注意事项
有几个关于ICP的事情要注意:
- ICP 只能用于二级索引,不能用于主索引;
- 也不是全部 where 条件都可以用 ICP 筛选,如果某 where 条件的字段不在索引中,当然还是要读取整条记录做筛选,在这种情况下,仍然要到 server 端做 where 筛选;
- ICP 的加速效果取决于在存储引擎内通过 ICP 筛选掉的数据的比例;
总结建索引的几大原则
1、最左前缀匹配原则,非常重要的原则,MySQL 会一直向右匹配直到遇到范围查询 (>、<、between、like)就停止匹配;
2、= 和 in 的条件可以乱序;
3、尽量选择区分度高的列作为索引,区分度表示字段不重复的比例,比例越大我们扫描的记录数越少;
4、索引列不能参与计算,保持列「干净」。原因很简单,b+ 树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。
5、尽量的扩展索引,不要新建索引。
索引是最好的解决方案吗?
索引不是最好的,但已经是相当好的了。
当表非常小时,没必要使用索引,直接全表查询好了;
当表是中大型时,比较适合使用索引,来快速定位目标数据;
当表是超大型时,创建和维护索引都是不小的代价,需要专业的 DBA 来分析,这种情况下可以尝试使用分表技术;
参考:
https://blog.csdn.net/u012006689/article/details/73195837
http://lihx8.lofter.com/post/1cc9bc99_7da03fe


