我们之前学习了隔离级别和锁,在隔离级别里有一个可重复读,锁里有个行锁。
- 可重复读:事务期间,看不懂别的事务的更新;
- 行锁:有事务 1 在更新某行数据时,若有其他事务 2 进来,会被锁住
矛盾来了:事务 2 等待结束,获取到行锁时,看到的是哪个数据呢?
按可重复读隔离级别来说,看到的应该是事务启动时的最新数据,即事务 1 修改之前的数据;
但是这样不就造成了事务 1 的修改丢失了吗?
本文脑图:https://mubu.com/doc/hyPYP01r-G
话不多说,我们先手动实验一把。
实验
我们建个表先:
1 | mysql> CREATE TABLE `t` ( |
然后做如下操作:

说明:
1、begin/start transaction 运行后其实并不会立即启动事务,执行第一个操作 InnoDB 表的语句时才会真正启动;
2、显示启动事务:start transaction with consistent snapshot
很容易看到实验结果:
- A 读到的值是 1
- B 读到的值是 3
看上去 B 事务违反了可重复读隔离级别的概念,为啥呢?
原因探索
之前在学习事务隔离级别时,我们接触到了一个「视图」的概念,这个视图和我们平常接触的 view 视图并不一样。
MySQL 中的两个「视图」的区别
一、常说的视图:view
① 是用查询语句定义的虚拟表;
② 在调用时执行查询,并生成结果;
③ 创建方法:create view...;
二、MVCC 中的一致性视图(consistent read view)
① 用于支持隔离级别的实现:RC(Read Committed,读提交)和 RR(Repeatable Read,可重复读)
② 没有物理结构,作用是事务执行期间用来定义我能看到什么数据;
③ 其中,可重复读:每个事务启动是都会重建读视图,整个事务存在期间都用这个视图;
快照是什么
很多文章都会说可重复读隔离级别下,事务启动时会生成整个库的快照。
那么这个快照是什么?
我们要先了解下数据的版本问题:
其实每个事务都有一个标识 id:trx_id,是在事务启动时向存储引擎的事务系统申请的,并且是按照申请顺序严格递增的。
每行数据都有版本的概念,这里的版本其实就是修改历史,而这个修改历史是跟事务挂钩的,比如:
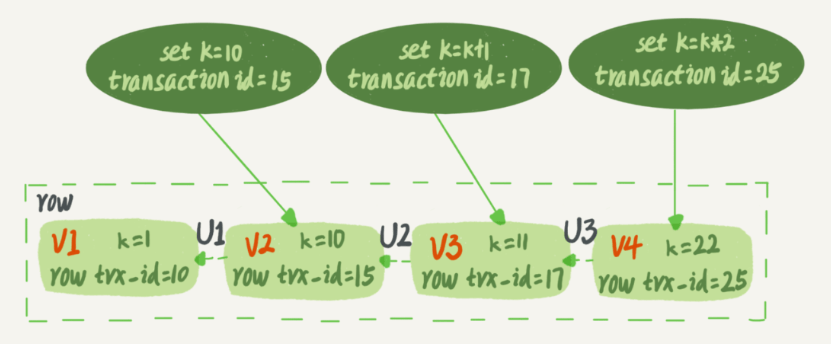
如图所示,一行数据被多次事务修改时,这行数据会存储多个版本,如 V1、V2、V3 等。
每个版本会记录了关联的事务 id,这里的版本并不是物理上存在的,需要根据版本号+undo log 来获取。
其实,快照就是版本号的集合。
事务启动时发生了什么
可重复读隔离级别下,事务的属性是这样的:可以看到所有已提交的更新,所有未提交的更新都不能看到。对于同一行数据,以最新一次的事务提交为数据基准。
另外,事务启动后,很可能存在其他活跃事务(启动且未提交),我们把这些活跃事务的 id 组成一个数组,并且记数组中 trx_id 最小的记为低水位,trx_id 最大的记为高水位。
因此,所有的事务 id 可以分成下图这种:
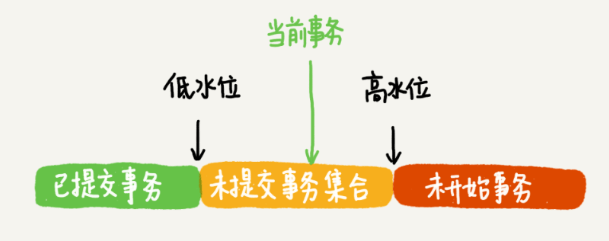
- trx_id 在绿色部分,已提交,可见
- 在红色部分,未提交,不可见
- 黄色部分
- trx_id 在数组中,未提交,不可见
- trx_id 不在数组中,已提交,可见
举个例子
1、假设有一组事务 id:[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12];
2、其中已提交(可见):[1, 2, 3, 6, 7],未开始的(不可见):[10, 11, 12],当前 id:[8]
3、那么活跃 id 数组(不可见):[4, 5, 9],高水位:9,低水位:4;
4、高低水位之间既有已提交但不在数组中的(可见):[6, 7],又有活跃的(不可见):[4, 5, 9]
实验复盘
按照上面的数组和水位的概念,我们来捋一下文章开头的实验。
首先,假设事务 A 的 id 为 10,启动后,A 的活跃数组就是 [10];
接下来是事务 B,id 为 11,启动后,B 的活跃数组是 [10, 11];
最后是 C,id 为 12,启动后,活跃数组是 [10, 11, 12];
C 处理完毕后,直接提交事务;k 的值由 1 变为 2,
此时就存储了两个版本的数据:(事务id-9, 1),(事务id-12, 2)
接下来 B 来处理,它会将 k 的值更新为 3,此时就有三个版本的数据:(事务id-9, 1),(事务id-12, 2),(事务id-11, 3)
最后 A 事务,由于 A 启动时,B、C 事务都未提交,所以它们的数据更新对于 A 来说都是看不到的,因此 A 获取到的结果是 1。
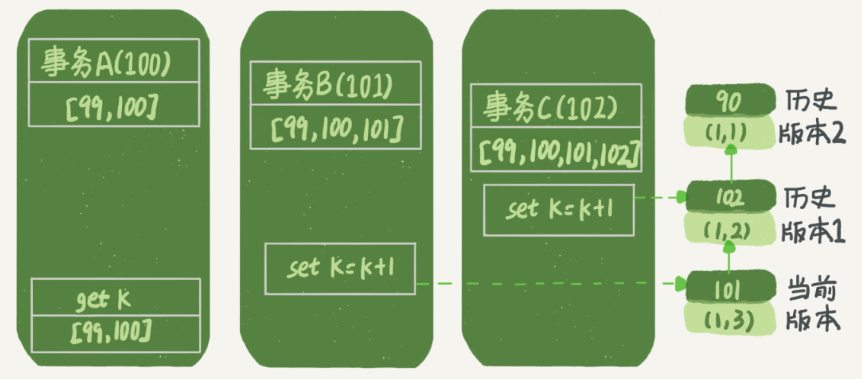
更新的逻辑
不知道你注意到没有,上面的复盘中,有一个重要的点,我们没有说。
按照可重复读的逻辑,B 执行更新时,看到的 k 的值应该是 1,执行更新的话,就直接造成了 C 操作中的数据丢失。
但是事务 B 在更新时,为什么读取到了事务 C 更新的数据?
这里有一条规则,就是更新数据都是先读后写的,而这个读,只能读当前的最新值,称为当前读(current read),
即,更新数据时总是读取已经提交完成的最新版本。
另外,除了 update 语句外,select 语句如果加锁,也是当前读。
1 | 读锁(S 锁,共享锁):mysql> select k from t where id=1 lock in share mode; |
总结
可重复读的能力是怎么实现的?
把握以下几点:
1、可重复读的核心就是一致性读(consistent read);
2、而事务更新数据的时候,只能用当前读。
3、如果当前的记录的行锁被其他事务占用的话,就需要进入锁等待。
另外,本文的几个重要概念:
1、一致性视图,保证了当前事务从启动到提交期间,读取到的数据是一致的(包括当前事务的修改)。
2、当前读,保证了当前事务修改数据时,不会丢失其他事务已经提交的修改。
3、两阶段锁协议,保证了当前事务修改数据时,不会丢失其他事务未提交的修改。
4、RR 是通过事务启动时创建一致性识图来实现,RC 是语句执行时创建一致性识图来实现
课后题目
我们用下面的语句初始化一个表:
1 | mysql> CREATE TABLE `t` ( |
你是否可以尝试制造出下面的「诡异」现象?

诡异之处在于,我们的目的是将“字段 c 和 id 值相等的行”的 c 值清零,但是发现更新语句执行成功后,c 的值并没有被清零!
答案
我们用如下操作流程就可以:
| 事务 A | 事务 B | 查询结果 |
|---|---|---|
| start transaction with consistent snapshot; | ||
| start transaction with consistent snapshot; | ||
| select * from t; | 1 2 3 4 | |
| update t set c = 5; | ||
| commit; | ||
| update t set c = 0 where id=c; | ||
| select * from t; | 1 2 3 4 | |
| commit; | ||
| select * from t; | 5 5 5 5 |
原因分析
主要原因就算当前读!
事务 B 是在事务 A 之后启动的,但是事务 B 的更新提交是在 事务 A 之前。
事务 A 第一次查询时,由于可重复读,读取到的自然是 1 2 3 4。
事务 A 更新时,根据当前读规则,此时 c 的值已经是 5,不再满足更新条件 id=c,因此更新不会真正执行。
所以,事务 A 再次查询时,获取到的仍然是 1 2 3 4,事务 A 提交后,再查询时,获取到的自然是最新的数据了。


