两种:
- 全字段索引
- 前缀索引
举例:
1 | mysql> create table SUser( |
可以对 email 字段创建全字段索引,或者前缀索引。
1 | mysql> alter table SUser add index index1(email); |
区别
1、全字段索引占用空间大,前缀索引占用空间小;
2、全字段索引查询效率高,前缀索引则会增加额外的记录扫描次数。
执行过程
1 | select id,name,email from SUser where email='zhangssxyz@xxx.com'; |
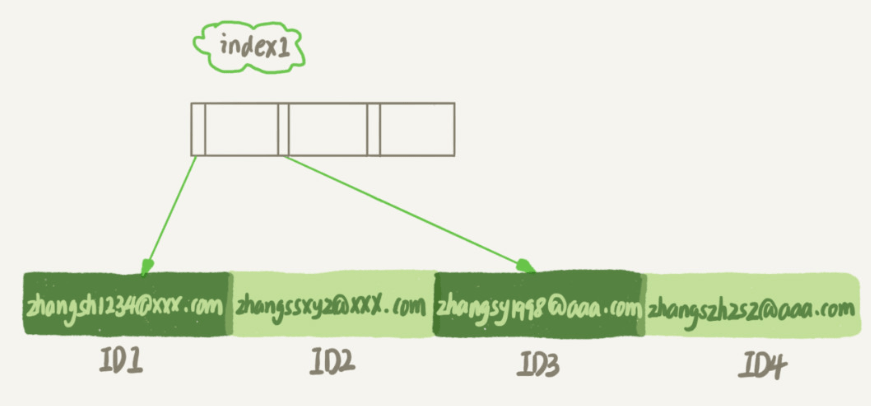
1、全字段索引
① 从 index1 索引树中找到索引值是 zhangssxyz@xxx.com 的记录,然后得到主键值;
② 根据主键值获取到该行的完整数据(回表),再判断 email 是否满足条件,将这行记录加入结果集;
③ 沿着索引树继续查找下一条满足条件的数据,若不满足,循环结束;
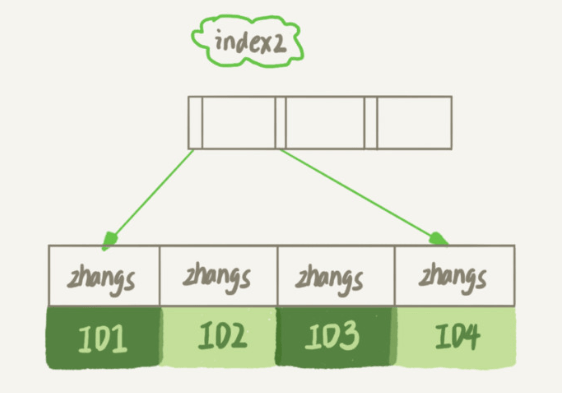
2、前缀索引
① 从 index2 索引树上查找索引值是 zhangs 的记录,找到一条后,得到主键值;
② 根据主键值获取到该行的完整数据(回表),再判断 email 是否满足条件,将这行记录加入结果集;
③ 沿着索引树继续查找下一条满足条件的数据,发现仍然满足条件,重复上面的操作;
④ 重复上一步,直到在 index2 上取到的值不满足条件,循环结束。
很明显,使用前缀索引,导致查询次数增多。
如何减少前缀索引查询次数?
区分度,区分度越高,前缀重复的可能性越小,进而,查询次数就越少。
通过如下语句,可以查询到不通前缀长度,分别有多少个不同的值:
1 | mysql> select |
自己可以预先设定一个可以接受的重复比例,比如大于 L * 95%。
前缀索引对覆盖索引的影响
使用前缀索引将无法利用覆盖索引的优化。
查询时,系统并不确定前缀索引的定义是否截断了完整信息。
前缀索引的优化
1、倒序存储
适合字段值前面部分重复度高,后半部分重复度低,这时可以倒序存储数据。
查询时可以这么写:
1 | mysql> select field_list from t where id_card = reverse('input_id_card_string'); |
2、做 hash
新增一个字段,专门存储字段的 hash 值:
1 | mysql> alter table t add id_card_crc int unsigned, add index(id_card_crc); |
每次插入数据时,都要调用 crc32() 这个函数得到校验码填到这个新字段。
这个字段有可能重复,需要联合判断 id_card 的值是否精确相同。
1 | mysql> select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string' |
二者的区别
1、都不支持范围查询
2、hash 字段需要额外的空间
3、CPU 消耗:倒序插入时需要额外调用 reverse 函数,hash 需要调用 crc32() 函数。reverse 函数消耗的 CPU 更小一些;
4、hash 字段方式的查询效率更高,因为计算出来的 hash 值重复的可能性较小,扫描次数接近于 1
总结
1、直接创建完整索引,这样可能比较占用空间;
2、创建前缀索引,节省空间,但会增加查询扫描次数,并且不能使用覆盖索引;
3、倒序存储,再创建前缀索引,用于绕过字符串本身前缀的区分度不够的问题;
4、创建 hash 字段索引,查询性能稳定,有额外的存储和计算消耗,跟第三种方式一样,都不支持范围扫描。
如何选择?
当数据量大时,一个学校每年预估 2 万新生,50 年才 100 万记录,能节省多少空间,直接全字段索引。省去了开发转换及局限性风险,碰到超大量迫不得已再用后两种办法。从业务量预估优化和收益,这不失为一个不错的想法。


