有如下 SQL 语句:
1 | select city,name,age from t where city='杭州' order by name limit 1000 ; |
执行流程是怎样的?
全字段排序
MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer。
这里使用 city 作为查询条件,为了避免全表扫描,可以在 city 上加上索引。
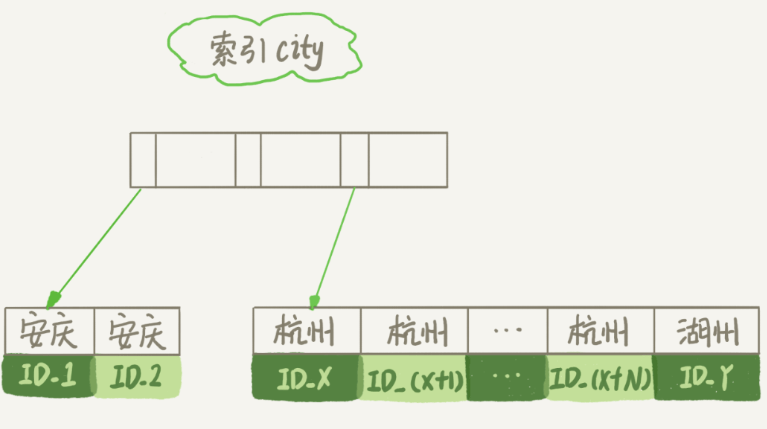
上面语句的执行流程如下:
1、初始化 sort_buffer,确定放入 city、name、age 三个字段;
2、从索引中找到第一个满足 city 条件的主键 id;
3、回表,根据主键 id 取出整行数据,取 city、name、age 三个字段的值,存入 sort_buffer;
4、重复步骤 2、3,这样所有满足 city 条件的字段,并存入到了 sort_buffer 中;
5、对 sort_buffer 中的数据按字段 name 做快速排序;
6、按照排序结果取前 1000 行返回给客户端。
执行流程如下图所示:
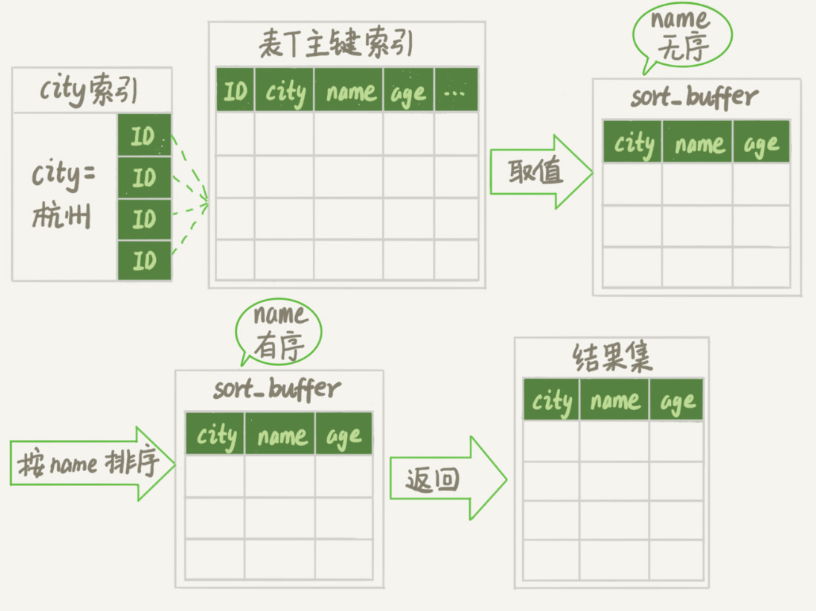
可以看出,排序是在 sort_buffer 中完成的,若 sort_buffer_size 的大小不足以放下待排序的数据,那么就需要借助磁盘临时文件来完成。
你可以用下面介绍的方法,来确定一个排序语句是否使用了临时文件。
1 | /* 打开 optimizer_trace,只对本线程有效 */ |
这个方法是通过查看 OPTIMIZER_TRACE 的结果来确认的,你可以从 number_of_tmp_files 中看到是否使用了临时文件。
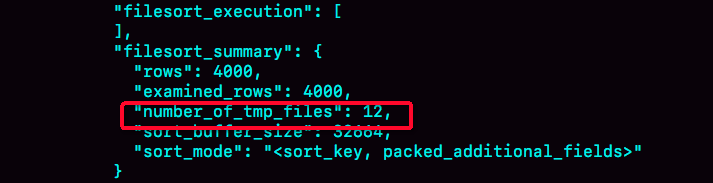
number_of_tmp_files 表示排序过程中用到的临时文件数。
内存放不下时,就需要使用外部排序,外部排序一般使用归并排序算法。可以这么简单理解,MySQL 将需要排序的数据分成 12 份,每一份单独排序后存在这些临时文件中。然后把这 12 个有序文件再合并成一个有序的大文件。
examined_rows 表示参与排序的行数是 4000 行。
sort_mode 里面的 packed_additional_fields 的意思是,排序过程对字符串做了“紧凑”处理。即使 name 字段的定义是 varchar(16),在排序过程中还是要按照实际长度来分配空间的。
rowid 排序
上述算法中,只对原表中的数据读了一次,剩下的操作都是在 sort_buffer 和临时文件中进行的,如果要返回的字段过多时, sort_buffer 明显放不下,这样就要用到很多临时文件,排序性能就会很差。
1 | SET max_length_for_sort_data = 16; |
max_length_for_sort_data,是 MySQL 中专门控制用于排序的行数据的长度的一个参数。它的意思是,如果单行的长度超过这个值,MySQL 就认为单行太大,要换一个算法。
新的算法放入 sort_buffer 的字段,只有要排序的列(即 name 字段)和主键 id。
新算法的执行流程:
1、初始化 sort_buffer,确定放入 name、id 两个字段;
2、从索引中找到第一个满足 city 条件的主键 id;
3、回表,根据主键 id 取出整行数据,取 name、id 的值,存入 sort_buffer;
4、重复步骤 2、3,这样所有满足 city 条件的字段,并存入到了 sort_buffer 中;
5、对 sort_buffer 中的数据按字段 name 做快速排序;
6、遍历排序结果,取前 1000 行,按照 id 再去原表查询 city、name 和 age 三个字段返回给客户端。
如下图:
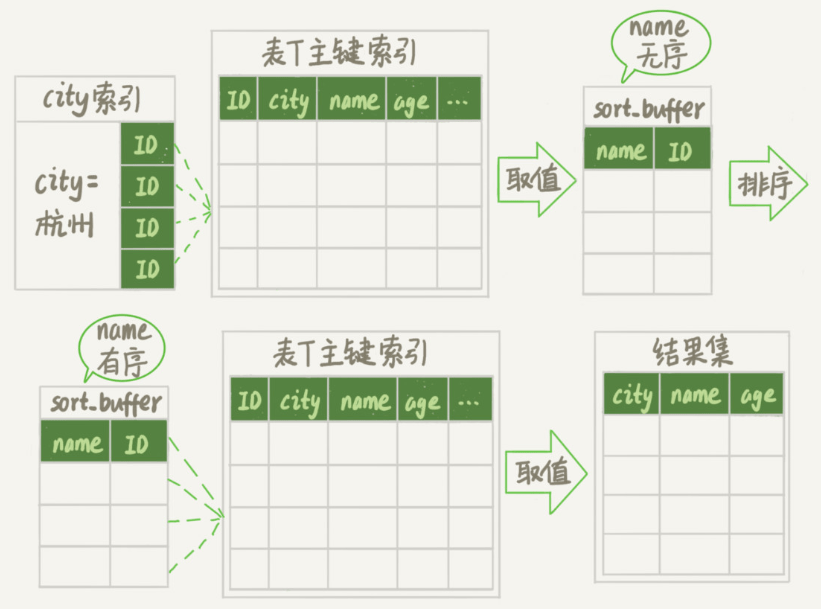
全字段排序 VS rowid 排序
如果担心内存小,影响排序效率,才会采用 rowid 排序算法,但是需要回到原表查询结果;
如果内存足够大,MySQL 会优先选择全字段排序。
体现了 MySQL 的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。
优化
如果能够保证从 city 取出的数据已经是按 name 递增排序的,那就不用再排序了。
比如,这样的联合索引:
1 | alter table t add index city_user(city, name); |
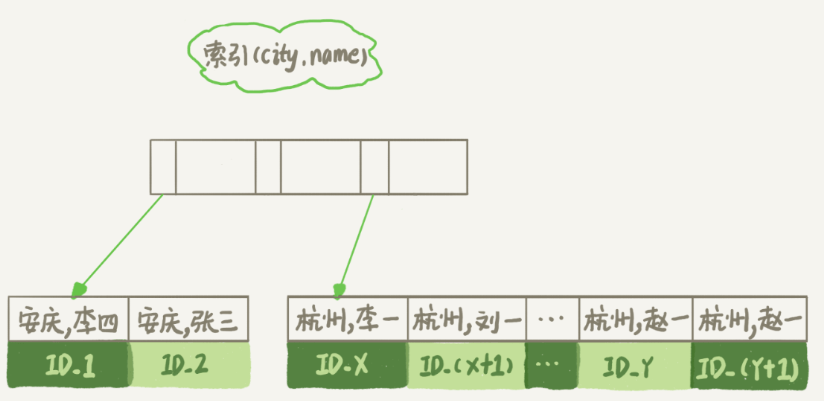
那么查询流程就变成了这样:
1、从索引 (city,name) 中找到第一个满足 city 条件的主键 id;
2、回表,根据主键 id 取出整行数据,取 city、name、age 三个字段的值,作为结果集直接返回;
3、重复 1、2 步骤,直到 city 条件不再满足;
如图:
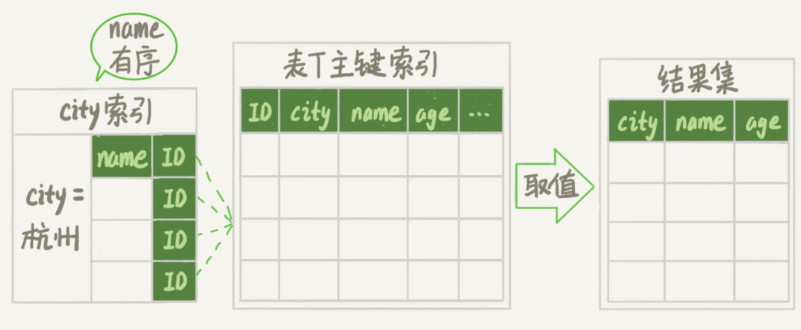
还可以利用覆盖索引,继续优化,减少回表的步骤!
1 | alter table t add index city_user_age(city, name, age); |


