这次我们来到了第五关,也是最后一关了,之后黑板客上就没再更新关卡。
且闯且珍惜吧~
相较于之前的关卡,本关多了验证码识别的功能,也就是需要对图片验证码进行自动识别。
第五关地址:http://www.heibanke.com/lesson/crawler_ex04/,页面如下:
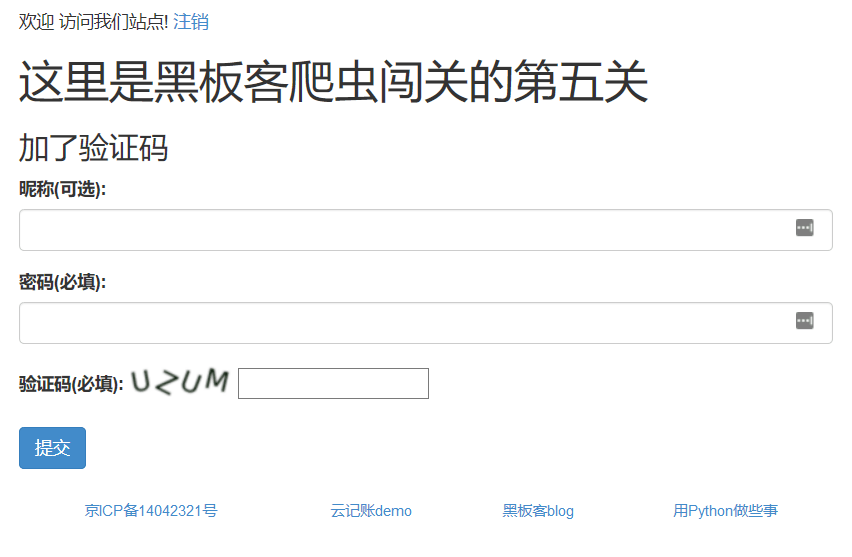
思路其实基本和第三关类似,主要是多了验证码的处理。
可以看出,验证码都是英文大写,并且位置不正,歪扭七八的,这给验证码识别带来了难度。
解题思路
先来看一眼请求数据:
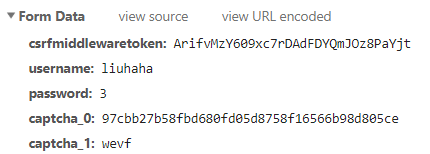
- username
- csrfmiddlewaretoken
- password
- captcha_0
- captcha_1
根据之前的闯关经验,1、2 两项我们都知道。password 我们也只能按照第 2、3 关密码 0~30 尝试。captcha_0 是登录页面上一个隐藏的值,对应的应该是验证码在服务器的 uuid。captcha_1 即验证码。
目前验证码处理仍然是一个比较困难的问题,处理方法一般可以分为自动识别和手动识别。
- 手动处理:就是通过验证码链接将验证码图片下载到本地,然后手动敲入完成信息录入。
- 自动识别:指使用一些高级的算法技术来完成的,如 OCR 文字识别,机器学习进行识别训练等。一般免费的文字识别算法识别率并不高,收费的识别效率还是可以接受的。
我们先体验一把自动处理,知道处理效果后,再考虑是不是用手动处理。
自动识别验证码
处理流程如下:
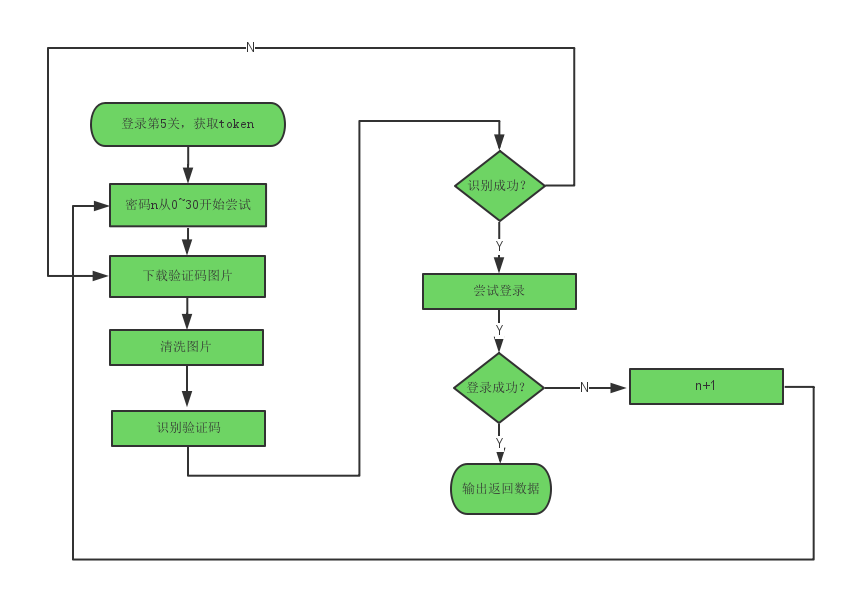
这里我们打算使用 Tesseract 进行自动图片识别的尝试。
tesseract-ocr 是一个做图形识别必须用到第一个软件,不仅可以处理验证码,也可以识别图片上的文字等等。其他的这里不再赘述,请自行 Google。
安装可以参考官方文档:https://github.com/tesseract-ocr/tesseract/wiki
试用下
准备好待识别的图片
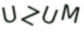
1 | # tesseract test.png result -l eng |
可以看出,识别成功,难道识别率这么好吗?
安装其他依赖组件
1 | pip install PIL |
Pytesseract 是一个 python 的第三方的包,主要作用就是用来连接操作 tesseract-ocr 工具。为我们用 python 来处理图形打好了基础。
Pillow 包是 python 的图形处理库,用来处理调整图形的各种内容。
实现
准备工作差不多了,下面就动手写代码吧!
1 | def getImage(): |

这里我对一些乱码进行了过滤,不过识别结果还是惨不忍睹啊!获取了 447 次,最后终于成功。

数据训练
识别率很差,但是 tesseract 是可以自行训练的,这样也许能够提升识别率。
训练过程很漫长,这里就不再展开,有兴趣的可以参考 https://www.cnblogs.com/zhongtang/p/5555950.html 中的方法进行训练。
这里只说下训练结果。
刚开始使用 100 张图片进行训练,但是结果还是不能令人满意,识别的正确率大概只有 10% 左右。
于是我又拉了 500 张图片,并用上次训练的结果再进行训练,这次后很少出现特殊字符了,说明还是有一点效果的,我只能这么安慰自己。
但是正确率还是很低!

也许还可以用 TensorFlow 来试一把,我现在实在没力气折腾了,有兴趣的搞一下看看?
另外,百度、腾讯等也有免费的图像识别服务,后面有兴趣我会进行测试,与大家分享。
手动识别
手动识别其实就是通过验证码链接将验证码图片下载到本地,然后手动敲入完成信息录入。
1 | def getImage(): |
需要每次运行时手动输入验证码,运行结果如下:
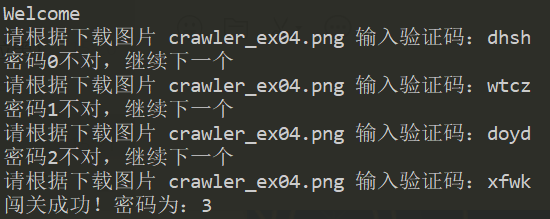
还好运行到 3 就成功了。
总结
本关的难点就是验证码的处理,用自动识别方法,识别率不高,当然这里我只用了一种方法,有做这方面工作的同学可以尝试用 TensorFlow 来试一把,记得来分享~
后续,我会测试下 百度、腾讯、阿里的图像识别接口,看下它们的识别情况是否能够让人满意,到时再给大家分享。
到这里,爬虫闯关系列就结束了,一共 5 关。通过这 5 关,我们大致了解了爬虫的一般流程,其中涉及了 cookie 处理、验证码处理、多线程爬虫等知识点,当然不能完全覆盖爬虫所有的知识点,但是我觉得足以应对一般网站的爬取了。


