最近一周一直在帮家里小弟看高考志愿,所以更新的没那么频繁了,请大家见谅。
在看各高校的往年分数时,忍不住手痒,想着能不能给它爬下来?哈哈,说干就干!
1 流程分析
之前无意中在这个网站发现有各个高校的历年录取分数线:https://gkcx.eol.cn。
我们的目标是用 Python 将下面页面的数据导出到 Excel:
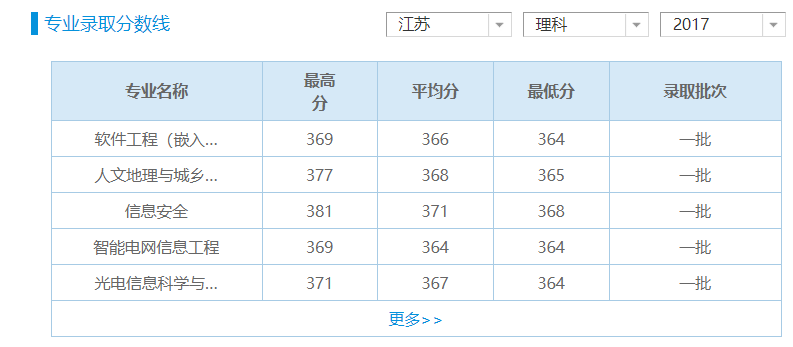
这个页面的 URL 是:https://gkcx.eol.cn/schoolhtm/schoolTemple/school160.htm,显然是需要一个 school_id 拼接而成的,那么如何获取这个 school_id 呢?
除非想办法爬取到所有院校的 school_id,这里我想着是从上面图中的搜索框进入:
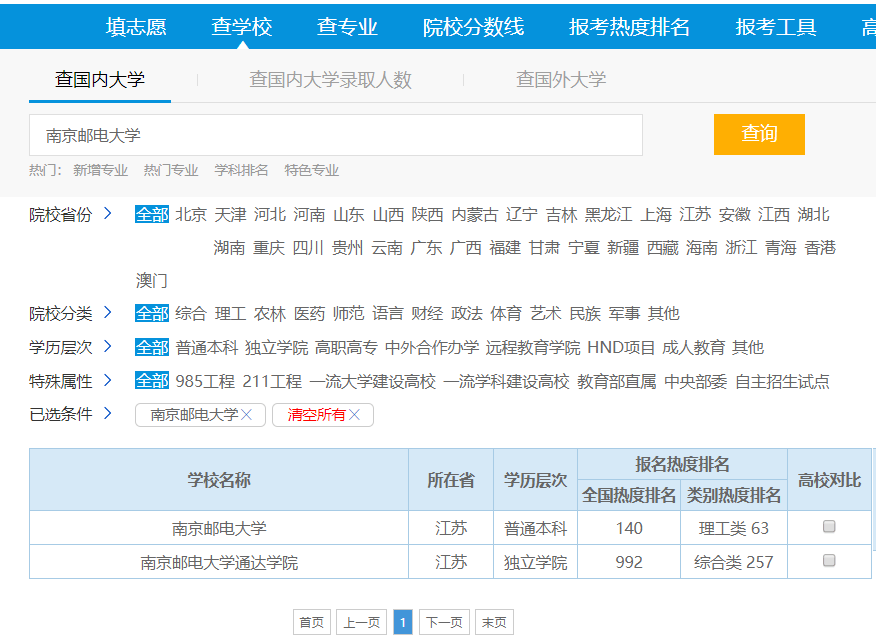
这样,整体的业务流程我们就理清楚了:
- 先调用搜索的 URL 获取到高校的 school_id,拼接到高校的详情访问地址
- 访问详情地址,抓取目标数据
- 处理目标数据,存储到 Excel 中
2 获取 school_id
按下 F12,可以看出搜索调用的 URL 是:https://gkcx.eol.cn/soudaxue/queryschool.html?&keyWord1=南京邮电大学,但是我们发现该请求的 response 里并没有高校列表,所以猜测这里是有二次数据请求获取到高校的列表,然后解析显示到页面的。
顺着请求流,我们看到了这么一个请求:
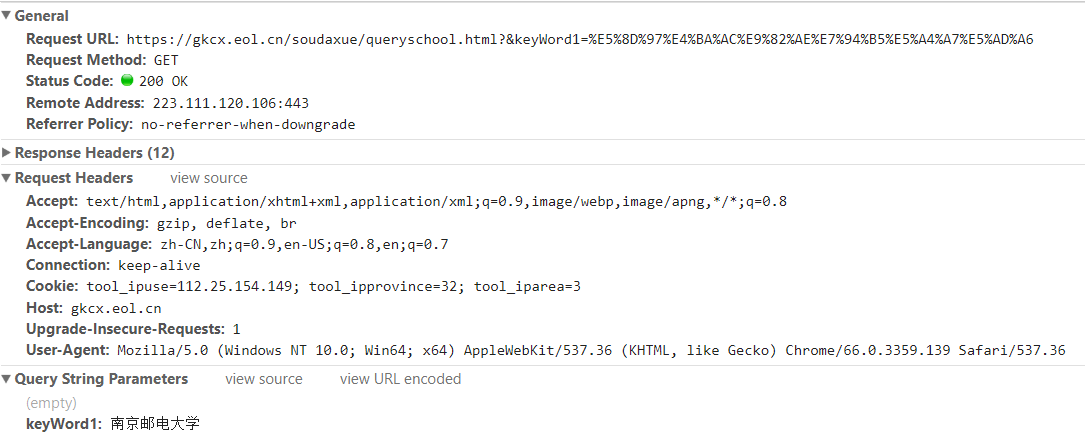
并且它的 response 刚好是一个包含高校信息的 json,到这里应该还是顺利的,我们只要从这个 json 里解析出我们想要的东西,然后继续后面的步骤就可以了。要注意该请求的 Referer。
但是在解析这个 json 时会遇到一个小问题,返回的数据格式是这样的:
1 | ({ |
它是被 (); 包围着的,不是一个合法的 json 数据,这里需要对其进行处理后才能解析 json:
1 | # 返回数据包含 ();,需要特殊处理 |
3 分数线获取
学校的详情页面是:https://gkcx.eol.cn/schoolhtm/schoolTemple/school160.htm,同样的套路,在点击后 response 里并没有分数线数据,我想也是二次请求吧,果然在请求流里找到了这个:
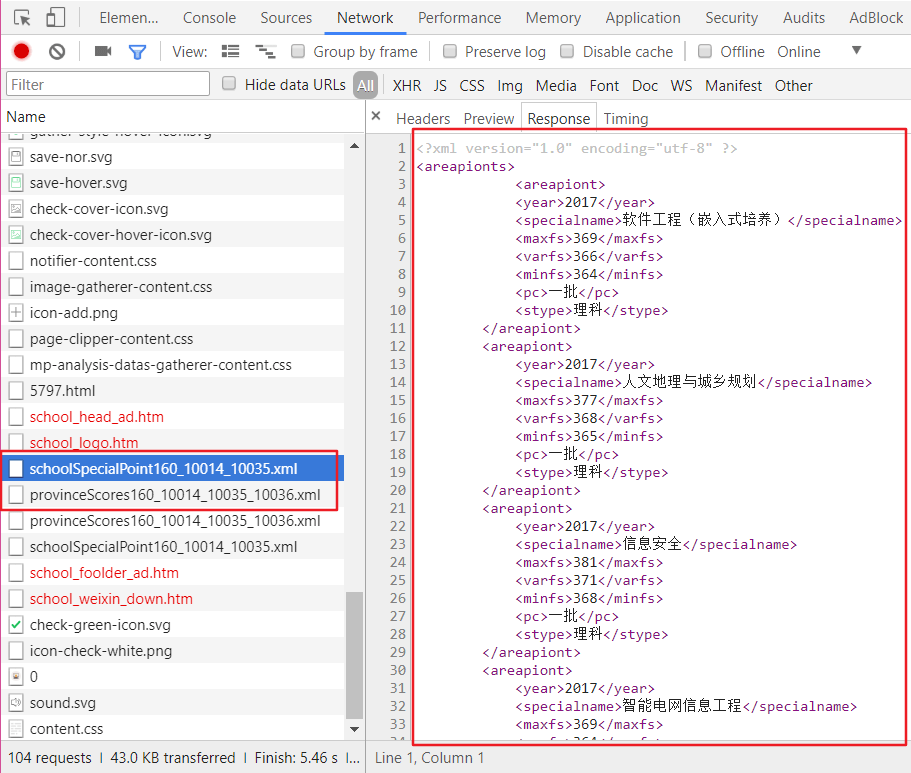
这里的两个请求刚好将高校的每年分数线和各专业的分数线以 XML 的格式返回,Very Good!
下面要做的就是 XML 解析啦。
4 XML 解析
这里我们使用 xml.etree.ElementTree 来解析 XML:
1 | <areapionts> |
由于数据比较规整,解析也很简单:
1 | areapionts = ET.fromstring(response.text) |
5 Excel 写入
Excel 的写入需要借助于 openpyxl 模块。
- openpyxl 简单使用示例
1 | import openpyxl |
- XML 解析写入 Excel
1 | def gen_excel(school,xml,wb): |
执行效果
1 | $ python gkcx.py |
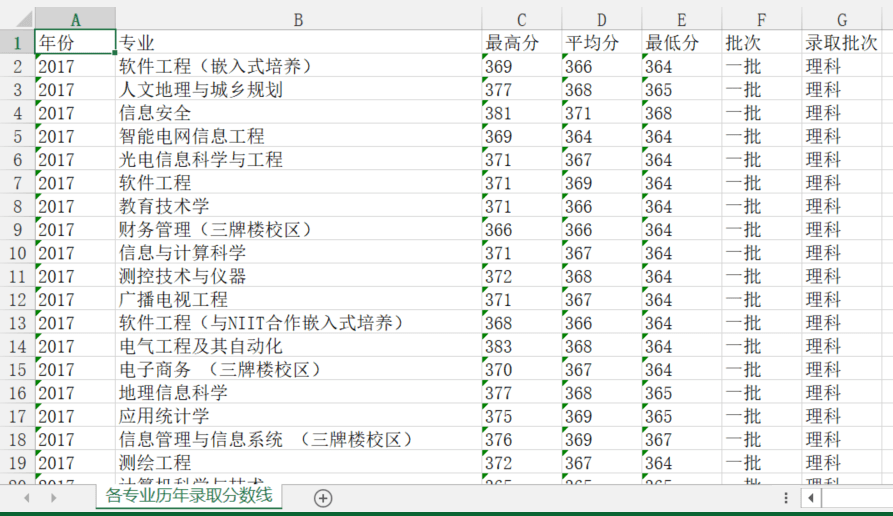
结果看着还可以,但是还是有问题的,因为各省的分数线肯定是不一样的,这里默认检索出的是学校所在省的分数线,因此若要获取在其他省的分数线,还需要进一步处理,有兴趣的同学不妨动手试一下。后台回复「高考」可以获取源码。
福利预告

随着公众号的壮大,最近开始有出版社找到我进行赠书的合作活动,我会在最近几天将活动发出,有兴趣的不妨关注下本公众号,等待福利降临!


