这次要抓取的目标是豆瓣电影 TOP250,主要是要的是 BeautifulSoup,一道美味的汤啊~ 🍵
解析
其实简单的网络爬虫无外乎查看网页源码,从源码中获取自己想要的东西,然后对其进行处理。
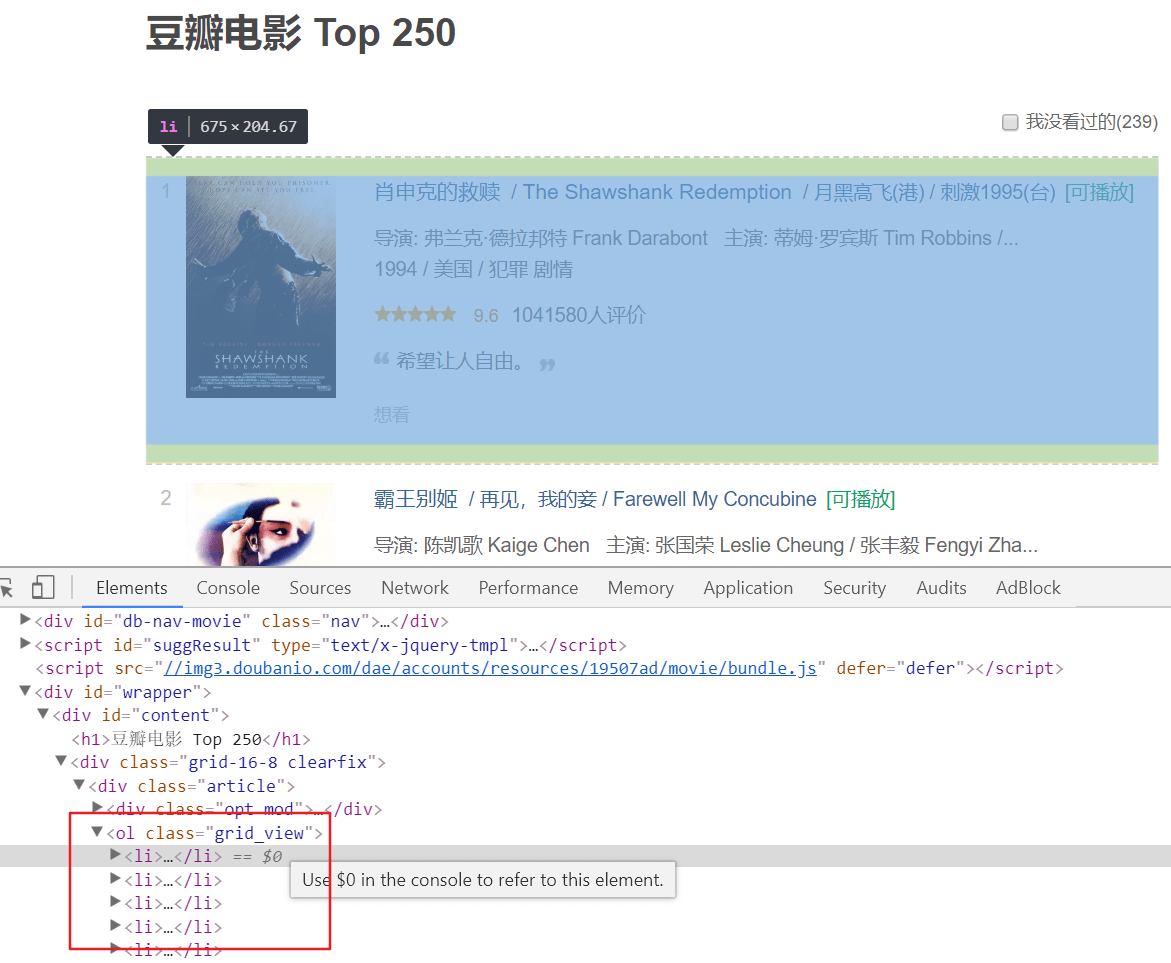
通过查看页面元素代码可以看出:
- 电影条目是被
<ol class="grid_view">所包围的; - 其中每个电影条目是一个
<li>; - 另外,每页有 25 个条目,共 10 页,这意味着需要解析多页数据。
我们来看下其中一个条目的源码:
1 | <li> |
对于每个条目,我们需要解析出其中的 电影名称、评分、评价人数,及一句话点评。
标题、评分、评价解析
标题是在 <span class="title">肖申克的救赎</span> 里的,我们可以使用
1 | find("span", attrs={"class": "title"}).getText() |
获取到,但是明显这里又多个 <span class="title">,那我们就只获取第一个,其他的不关心。
评分和评价的解析和标题类似,用同一种解析方法解析即可。
评价人数解析
评价人数这里是这样的: <span>1041580人评价</span>,明显跟上面的不同,它没有 class 属性,这里只能通过 text 来查找了:
1 | find(text=re.compile('人评价$')) |
这里用了正则表达式来进行匹配,即匹配以 人评价 结尾的文本。
下一页解析
1 | <span class="next"> |
对照代码,需要从中解析出下一页的连接 ?start=25&filter=。
解析方法类似于标题的解析,先解析出 <span class="next">,然后解析其中的 <a> 标签。
1 | find("span", attrs={"class":"next"}).find("a") |
要解析的东西基本上就是这些,最后需要将解析结果保存到文件。
实现代码
1 | # encoding:utf-8 |
运行结果
1 | $ cat doubanMoviesTop250.txt |
搞定,后面对 BeautifulSoup 的用法再进行一个详细的研究吧。


