最近打算抓取知识星球的数据,分析下大家喜欢发布哪方面的主题,用词云的方式展示出来。
请求参数分析
这里我们使用网页版进行爬取,首先用 Chrome 登陆知识星球,登陆成功后按下 F12 打开 Developer Tools,并进入查看网络请求窗口。
然后在页面点击一个订阅的星球,此时网络会去请求该星球的数据,肯定会有一个 topics?scope=digests&count=20 的 GET 请求,点击该请求,在请求头里会有一个 Authorization 参数,将该参数对应的值记下。该参数相当于一个认证 ID,在一段时间内一直有效,后面爬虫就会一直使用该数值请求数据。
网页版星球是没有分页的,后在下拉框到底部后自动加载,此时我们可以看到请求地址是:topics?count=20&end_time=2018-06-14T00%3A00%3A52.603%2B0800,是根据时间来进行请求的,这个请求应该满足我们按时段分析数据的需求。
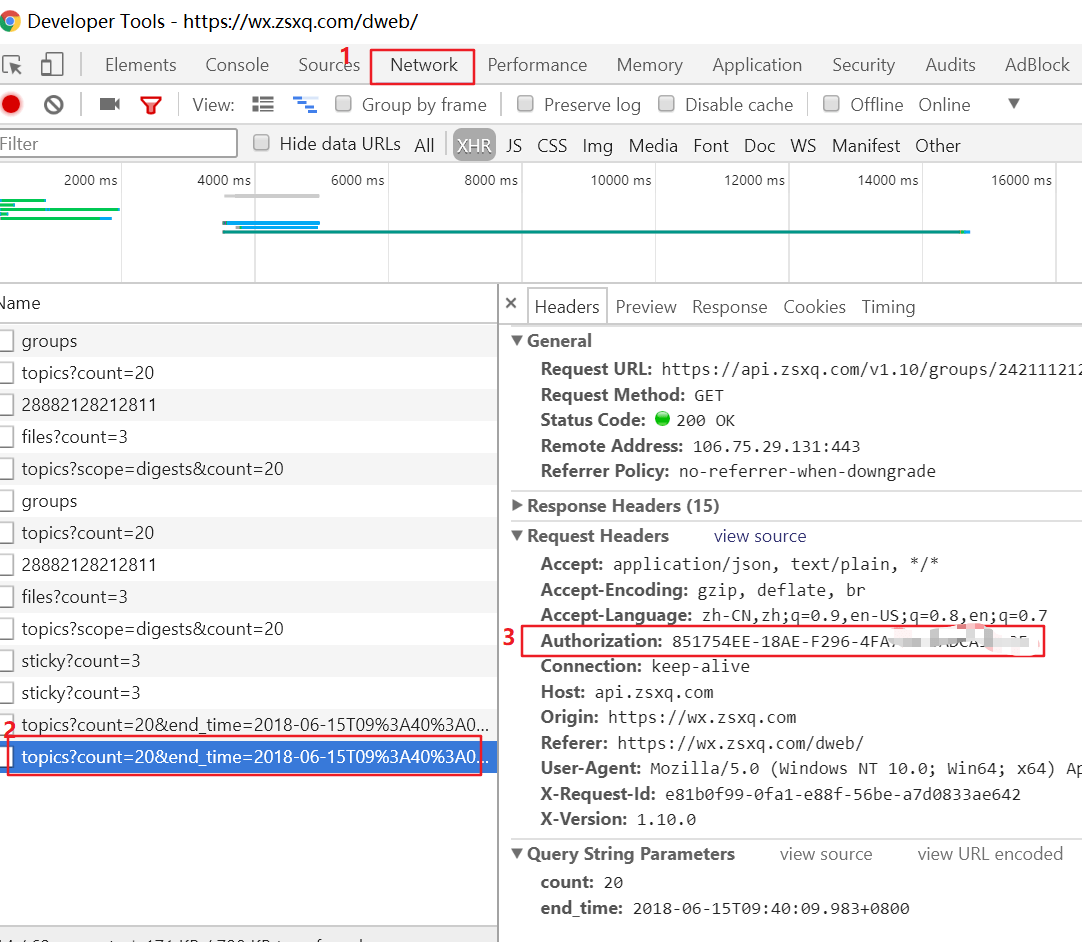
我们来分析 帅张和他的朋友们 的星球数据,其基本 URL 是 https://api.zsxq.com/v1.10/groups/2421112121/。
数据解析
用 Postman 测试接口,可以得到返回的数据是一大坨 json 数据,形如:
1 | { |
可以看出返回的数据是一个 topics 的 list,其中每个 topic 中包含着用户信息、主题内容、点赞数、评论数、评论内容、点赞者的信息、创建时间等等,我们可以使用 jsonpath 组件从返回数据中解析出我们想要的文本数据。
1 | jsonpath.jsonpath(result, "$..topics[*]..text") |
实现
准备工作
- 安装必要的组件:jsonpath、jieba、numpy、wordcloud 等;
- 准备字体文件,如本文的 fangsong_GB2312.ttf;
- 准备词云形状图片,如本文的 python.png;
词云展示的大致步骤如下:
- 读取本地的文件
- 使用 jieba 进行分词,并对分词的结果以空格隔开;
- 对分词后的文本生成词云;
jieba 分词
1 | f = open('result.txt').read() |
这样就可以得到一个分词后的 list 结果。
其实生成词云的 generate 函数是可以对全部文本进行自动分词,但是对中文支持不好,所以这里我们使用 jieba 先进行了分词。
生成词云
1 | coloring = numpy.array(Image.open("python.png")) |
其中参数含义如下:
- width,height,margin 可以设置图片属性
- 通过
font_path参数来设置字体集 - 通过
mask参数 来设置词云形状
另外,font_path:这个是在词云图中显示文字的字体存放的路径,特别是在显示中文的时候,这个参数尤为重要,如果缺省的话容易造成乱码,如下:

运行
1 | $ python zsxq_cloud.py -d "2018-06-13" |
运行成功后会在当前目录生成一个 test.png 的图片:

总结
可以看到,词云展示实现起来不过 10 行代码,数据的获取才是关键。这里我只是分析一天的数据生成词云,那么一个月的数据如何获取呢?大家不妨想一下。
另外,下回准备对星球数据换个方向进行分析,分析下大家喜欢在哪一天发文,在一天里的什么时候发文,且听下回分解~
代码已上传至 GitHub,点击阅读原文下载。


